技術說明
一、資料來源與預處理
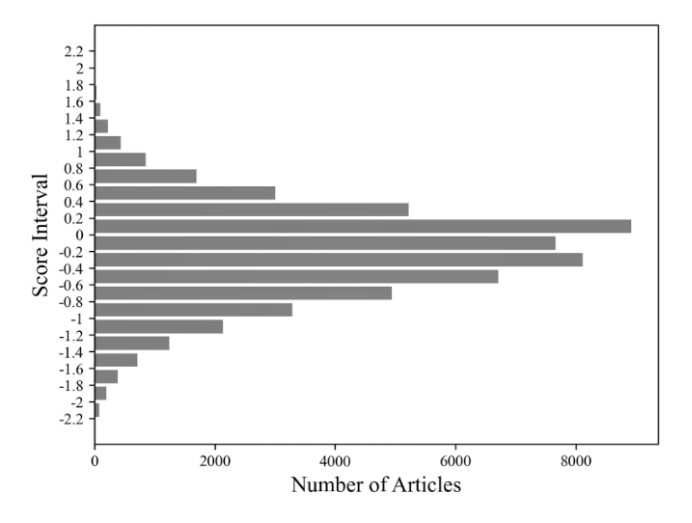
本計畫使用爬蟲工具蒐集 Dcard心情板與感情板2019年全年共55989篇文章的標題與內文作為本研究的資料庫(database)。接著使用National Taiwan University Semantic Dictionary(NTUSD)的情緒辭典[1]來評估文章的正負向情緒指數,篩選出負向情緒最高的文章來做資料標註:也就是計算每篇文章的總得分再除以總字數作為此文章的平均情緒指數。圖一即為此粗資料集中文章情緒指數的分布圖,而本計畫使用指數低於-1.4的1424篇文章作為A1資料集(Dataset)A1,進行專業人員標註。
二、人工標註結果
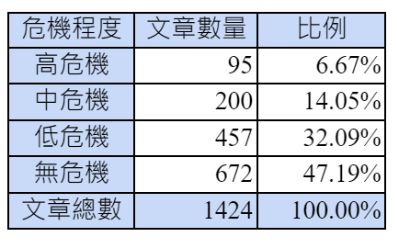
本計畫執行兩種專業人員標註,皆是由心理諮商領域的研究生在李昆樺教授的指導下,使用文字標註平台[2]進行相關的標註工作。標註的方式主要區分為類型標註與語意標註(或稱理據標註)兩種[2]:類型標註即是將文章依照其內容分為高度危機、中度危機、低度危機、無危機四個等級。其中高危機代表有明確的自殺行為或具體行動、中度危機代表有明確的自殺規劃或預備、低度危機代表有自殺的意圖或想法、無危機代表雖可能有各種情緒但是並無自殺的意圖[3]。以上四類文章在A1資料集中的數量與比例可參考圖一右方的表格。
語意標註是再針對這些文章中每個意義完整的句子進行初步標註,選出(1)自殺或自傷行為、(2)憂鬱與自殺意念、(3)無助感或無望感、(4)生理或醫療狀況、(5)其他負向文字、(6)正向積極文字、等六種類型的句子,並將其餘的標註為(7)中性或其他文字。為求標註的句子在文字長度上不會有太大的差異,在進行理據標註時已經先根據對網路文章換行書寫或以空格代替標點符號等特性與初步標註結果,確認平均長度為34.64字的句子已可表達大多數完整的語意,因此將文章先以下規則進行電腦斷句。
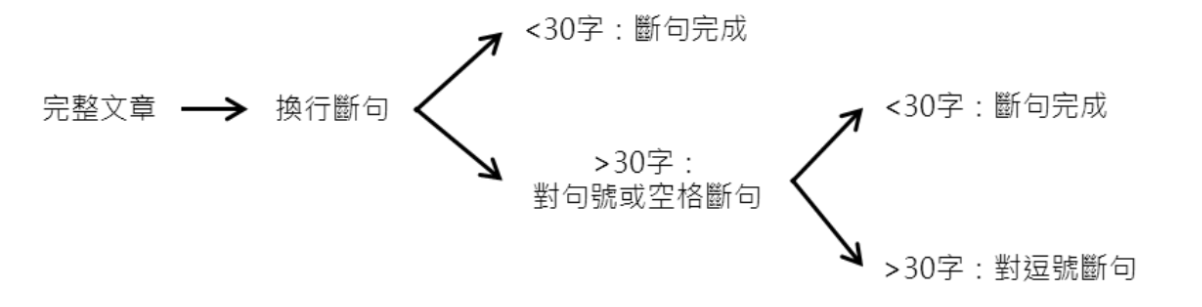
斷句後再將各句子進行標註,若單一句子同時符合多個標註,則以上述的順序優先選出次序最前的類別做為此句的標註。其他更詳細的資料說明請見研究團隊未來發表的心理相關領域文章[3]。本計畫針對A1資料集的標註結果如表一。
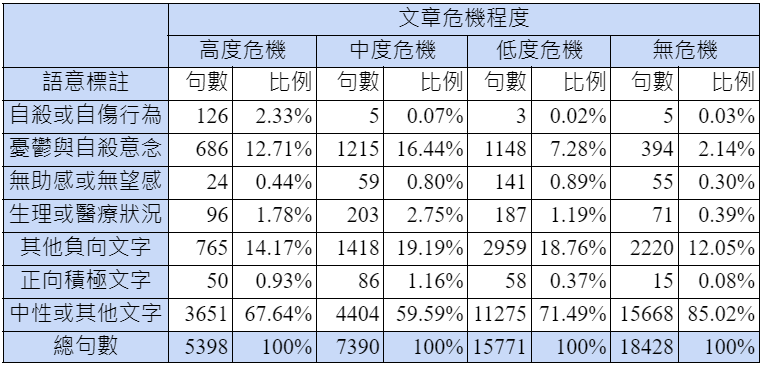
觀察上表可以發現,自殺與自傷行為基本上多出現於高度危機的文章,而若文章中包含大量憂鬱與自殺意圖和其他負向文字,則容易被區分為中度危機,若文章內容含有較多其他負向文字且憂鬱與自殺意圖的占比較少,容易被區分為低度危機。但是專業人員標註時並非僵化的根據這些述兩來作危機判斷,而這也是需要引入人工智慧來做語意判斷的原因。
三、機器學習作自殺風險偵測的系統架構
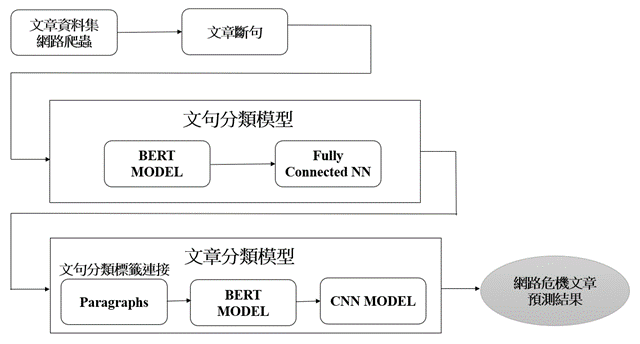
本計畫使用在人工智慧的自然語言處理技術(Natural Language Processing)中廣泛被使用的BERT(Bidirectional Encoder Representations from Transformers)作為預訓練模型[4](見圖二),使用本計畫的專業人員標註結果進行微調(fine-tune)。然而,從以上的圖一與表一可以看出,本研究所實際處理的資料集中的資料分布非常不平均(這並非本研究的問題而是實際資料的真實樣貌,與一般資工領域作為標準練習或比賽而篩選過的資料不同)。以文章的類型標註為例,「高度危機」的文章僅有70篇但「無危機」的文章卻有712篇。若以語意標註為例,「自殺或自傷行為」總共僅有139句,而「其他負向文字」則有7362句,數量上差距甚大。綜上所述,資料數量不多加上資料分布的不均勻為本研究開發模型過程中的主要問題,因此過程中我們針對資料做資料擴增(Data Augmentation),並結合半監督式模型(Semi-Supervised Learning)的技術來協助模型開發。其他詳細的技術說明請見研究團隊未來發表在資工領域的文章[3]。
四、語意分類模型的結果
本計畫中的語意分類目標是幫助文章分類模型提取重要的文句標籤,並不需要特別單獨強化對於所有類型的語意標籤進行模型優化,以節省時間與計算資源。因此本計畫先以其他較為簡單的機器學習模型(如XGboost)先行篩選出相對比較重要的語意標籤,得到「自殺或自傷行為」、「憂鬱與自殺意念」與「其他負向文字」三者為最重要考慮的因素(也恰好是非中性文字中,出現比例最高的三個,見表一)。因此本計畫先將語意標註的結果進行部分合併,將「無助感或無望感」與「生理或醫療狀況」併入「其他負向文字」,也將「正向積極文字」併入「中性或其他文字」。因此本計畫的機器學習的模型訓練與預測即為四分類模型。
經過訓練後,本計畫的語意分類模型對此四類文字所得到的準確度(precision)、召回率(recall)、和F1分數(F1-score)如表二:
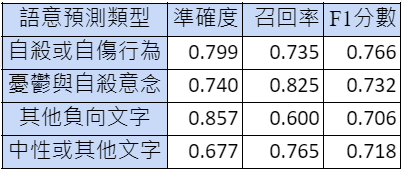
由表二可觀察到,由於分類的標籤種類變少,此四分類模型平均而言皆有較好的表現,對於每個文句種類的表現也都十分平均,F1-score約為0.7~0.76。
五、文章分類模型的結果
針對文章分類的預測模型來說,本系統的目標是能夠正確偵測出有「高度危機」的網路文章。因此,本研究在訓練文章分類模型時,將B、C、0三類文章合併成「中低危機」程度文章,成為二分類模型。表三是文章分類模型經測試後的結果:
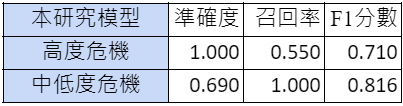
由表三可觀察到,本計畫的二分類文章分類模型能夠在高危機文章達到相當高的準確度,代表所預測出為高度危機的文章幾乎也都是與專業人員判斷符合的結果。但是由於其召回率僅有0.55,代表可能仍有若干應該是屬於高度危機的文章無法被偵測出來。此處本研究也使用ChatGPT4.0來做為應用的對照,依據同樣一批測試資料,我們發現ChatGPT的召回率相當高(將近1.000)但準確率較低,僅有0.714。
以上的結果代表作為通用的大型語言模型,其內在的設定是對於任何有負面情緒或自殺意念的文字都相當敏感,容易跳出警示,因此較能偵察出負面情緒但可能並無自殺危機的文章。也就是說在應用於真正大量的網路文章時,很容易提供過多的「偽陽性」結果,讓最後檢查的人員反而需要多花時間篩選,並非適合的模型。相較起來本研究採取的「提高準確率」的作法會比較符合實務現場的需求。畢竟面對每小時各網路平台可能有成千上萬的新貼文,危機處理又必須同時兼顧個人隱私的保護與時效性,降低偽陽性會是比較實際的需求與做法[5]。未來不排除結合不同模型的優點並擴大資料標註的數量,繼續開發出更精準且減少遺漏的網路危機文字偵測模型。
六、小結
本研究是透過跨領域的合作,將心理專業人員對於網路文章的自殺風險作專業標註,並且深入到文句的層次,可以有效避免大量無關的文字對文章風險判斷的稀釋或干擾,提升對於有自殺風險的高危機文章的判斷能力。本系統成功整合此機器學習模型至網頁前端而成為此測試版本,讓使用者能夠直接輸入相關的文章並獲得快速的分析結果。在進行社群網路高自殺風險的貼文識別上,有助於節省資源、降低誤判的機會,並且增加聯繫警政單位的時效性。研究團隊未來期待與心理、社政、警政並各大社群媒體平台合作,透過AI自動化的標註和分析,構建一個更加關懷與健康的社群媒體環境。
附註
[1] NTUSD的資料與說明可參考以下網址:https://rdrr.io/rforge/tmcn/man/NTUSD.html#google_vignette。NTUSD中包含8277個負向詞彙和2810個正向詞彙。
[2] 關於本計畫的專業標註方式與使用的工具,可以參考國立清華大學人文社會AI應用與發展研究中心所錄製的「文字標註系統導論線上課程」:https://nthuhssai.site.nthu.edu.tw/p/404-1535-238010.php
[3] 關於本計畫更多詳細的說明可見於研究團隊未來將逐一發表的論文(李昆樺2024)。
[4] 雖然在自然語言處理的研究中,過去一年因為ChatGPT的出現而開始轉向以大型語言模型(Large Language Model)為基礎發展的研究。本計畫也有針對若干開源的大型語言模型進行微調,但發現並沒有得到較好的結果,所以在此不作說明。
[5] 在本研究中若要提高對於高度危機文章的召回率相較起來是比較簡單的,只需要在訓練的時候將高度危機與中度危機的資料合併為「中高度危機」,然後與「低度或無危機」的文章區分開來,也依樣可以達到1.00的召回率。但是其代價就是對於真正高危機的文章的預測準確率也會降低,如同ChatGPT的結果。因此在實務上,這樣的方式應無法有效的節省最終篩檢定案的專業人員時間,不利於實際的系統部署或危機偵測的效果。